Dato un numero positivo , trova il numero di alcani con atomi di carbonio, ignorando gli stereoisomeri ; o equivalentemente, il numero di alberi senza etichetta con nodi, in modo tale che ogni nodo abbia grado .
Questa è la sequenza OEIS A000602 .
Vedi anche: Paraffine - Codice Rosetta
Esempio
Per , la risposta è , perché l' eptano ha nove isomeri :
- Eptano :

- 2-Methylhexane :

- 3-Methylhexane :

- 2,2- dimetilpentano :

- 2,3- dimetilpentano :

- 2,4- dimetilpentano :

- 3,3- dimetilpentano :
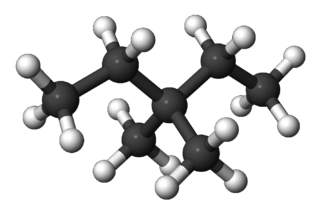
- 3-etilpentano :

- 2,2,3-Trimetilbutano :

Si noti che il 3-metilesano e il 2,3-dimetilpentano sono chirali , ma qui ignoriamo gli stereoisomeri.
Casi test
Non è necessario gestire il caso .
intput output
=============
0 1
1 1
2 1
3 1
4 2
5 3
6 5
7 9
8 18
9 35
10 75
11 159
12 355
13 802
14 1858
15 4347
16 10359
17 24894
18 60523
19 148284
20 366319
3
Sarei colpito se qualcuno riuscisse a scrivere una soluzione con Alchemist !
—
ბიმო
@PeterTaylor Bene Può emettere ogni volta una cifra
—
l4m2
@ l4m2: l'ho usato prima per una sfida di sequenza e alcune sfide numeriche , puoi anche usare un output unario che è molto probabilmente più facile. E sì, è molto probabilmente TC ( usa i bignum ), ma non l'ho provato formalmente.
—
ბიმო
@BMO Sembra solo in grado di simulare CM
—
l4m2