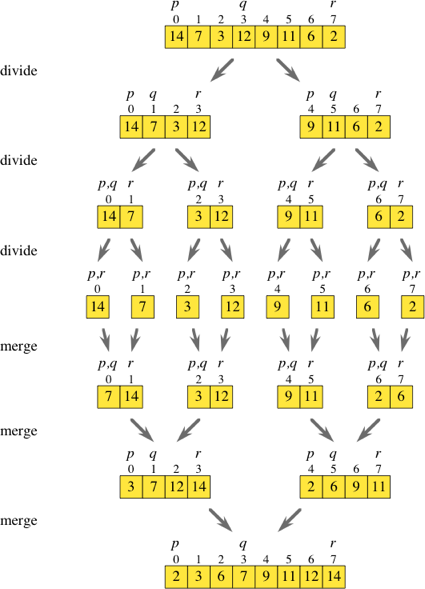
Quindi unire l'ordinamento è un algoritmo di divisione e conquista. Mentre stavo guardando il diagramma sopra, stavo pensando se fosse possibile bypassare sostanzialmente tutti i passaggi di divisione.
Se si scorreva sull'array originale mentre si saltava di due, è possibile ottenere gli elementi nell'indice i e i + 1 e inserirli nei propri array ordinati. Una volta che hai tutti questi sotto-array ([7,14], [3,12], [9,11] e [2,6] come mostrato nel diagramma), puoi semplicemente procedere con la normale routine di unione per ottenere un array ordinato.
L'iterazione attraverso l'array e la generazione immediata dei sotto-array richiesti sono meno efficienti rispetto all'esecuzione dei passaggi di divisione nella loro interezza?
Correlato: cs.stackexchange.com/questions/77075/…
—
Omar l'