Ho questa domanda da mesi. Sembra che abbiamo semplicemente indovinato il softmax come una funzione di output e quindi interpretiamo l'input del softmax come probabilità di log. Come hai detto, perché non normalizzare semplicemente tutti gli output dividendo per la loro somma? Ho trovato la risposta nel libro di Deep Learning di Goodfellow, Bengio e Courville (2016) nella sezione 6.2.2.
Supponiamo che il nostro ultimo livello nascosto ci dia z come attivazione. Quindi il softmax è definito come

Spiegazione molto breve
L'esp nella funzione softmax annulla approssimativamente il log nella perdita di entropia crociata causando una perdita approssimativamente lineare in z_i. Ciò porta a un gradiente approssimativamente costante, quando il modello è sbagliato, consentendogli di correggersi rapidamente. Pertanto, un softmax saturo errato non provoca un gradiente evanescente.
Breve spiegazione
Il metodo più popolare per addestrare una rete neurale è la stima della massima verosimiglianza. Stimiamo i parametri theta in modo da massimizzare la probabilità dei dati di allenamento (di dimensione m). Poiché la probabilità dell'intero set di dati di training è un prodotto della probabilità di ciascun campione, è più facile massimizzare la probabilità di log del set di dati e quindi la somma della probabilità di log di ciascun campione indicizzato da k:
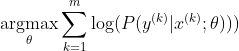
Ora, ci concentriamo solo sul softmax qui con z già indicato, quindi possiamo sostituirlo
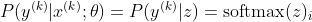
con la classe corretta del campione kth. Ora, vediamo che quando prendiamo il logaritmo del softmax, per calcolare la verosimiglianza del campione, otteniamo:
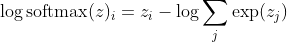
, che per grandi differenze in z si avvicina approssimativamente a
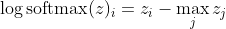
Innanzitutto, vediamo il componente lineare z_i qui. In secondo luogo, possiamo esaminare il comportamento di max (z) per due casi:
- Se il modello è corretto, max (z) sarà z_i. Pertanto, la probabilità logaritmica asintota zero (cioè una probabilità di 1) con una differenza crescente tra z_i e le altre voci in z.
- Se il modello non è corretto, max (z) sarà un altro z_j> z_i. Quindi, l'aggiunta di z_i non cancella completamente out -z_j e la probabilità di log è approssimativamente (z_i - z_j). Ciò indica chiaramente al modello cosa fare per aumentare la probabilità di log: aumentare z_i e diminuire z_j.
Vediamo che la probabilità di log complessiva sarà dominata da campioni, in cui il modello non è corretto. Inoltre, anche se il modello è davvero errato, il che porta a un softmax saturo, la funzione di perdita non si satura. È approssimativamente lineare in z_j, il che significa che abbiamo un gradiente approssimativamente costante. Ciò consente al modello di correggersi rapidamente. Si noti che questo non è il caso dell'errore al quadrato medio, ad esempio.
Spiegazione lunga
Se il softmax ti sembra ancora una scelta arbitraria, puoi dare un'occhiata alla giustificazione per l'uso del sigmoid nella regressione logistica:
Perché la funzione sigmoid invece di qualsiasi altra cosa?
Il softmax è la generalizzazione del sigmoide per problemi multi-classe giustificata in modo analogo.



