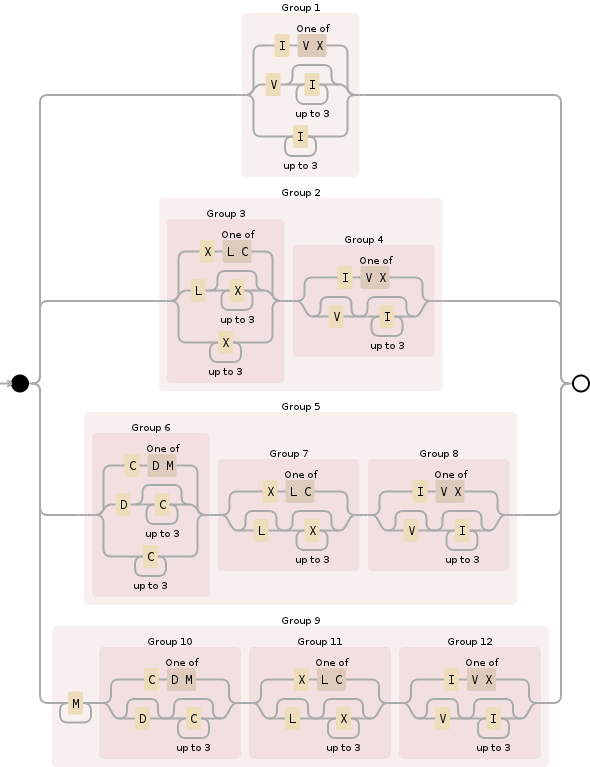
È possibile utilizzare la seguente regex per questo:
^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$
Abbattendolo, M{0,4}specifica la sezione delle migliaia e sostanzialmente la limita tra 0e 4000. È relativamente semplice:
0: <empty> matched by M{0}
1000: M matched by M{1}
2000: MM matched by M{2}
3000: MMM matched by M{3}
4000: MMMM matched by M{4}
Naturalmente, potresti usare qualcosa di simile M*per consentire qualsiasi numero (incluso lo zero) di migliaia, se vuoi consentire numeri più grandi.
Il prossimo è (CM|CD|D?C{0,3}), leggermente più complesso, questo è per la sezione centinaia e copre tutte le possibilità:
0: <empty> matched by D?C{0} (with D not there)
100: C matched by D?C{1} (with D not there)
200: CC matched by D?C{2} (with D not there)
300: CCC matched by D?C{3} (with D not there)
400: CD matched by CD
500: D matched by D?C{0} (with D there)
600: DC matched by D?C{1} (with D there)
700: DCC matched by D?C{2} (with D there)
800: DCCC matched by D?C{3} (with D there)
900: CM matched by CM
In terzo luogo, (XC|XL|L?X{0,3})segue le stesse regole della sezione precedente ma per il posto delle decine:
0: <empty> matched by L?X{0} (with L not there)
10: X matched by L?X{1} (with L not there)
20: XX matched by L?X{2} (with L not there)
30: XXX matched by L?X{3} (with L not there)
40: XL matched by XL
50: L matched by L?X{0} (with L there)
60: LX matched by L?X{1} (with L there)
70: LXX matched by L?X{2} (with L there)
80: LXXX matched by L?X{3} (with L there)
90: XC matched by XC
E, infine, (IX|IV|V?I{0,3})è la sezione di unità, la manipolazione 0attraverso 9e simili a due sezioni precedenti (numeri romani, nonostante la loro apparente stranezza, seguono alcune regole logiche, una volta a capire cosa sono):
0: <empty> matched by V?I{0} (with V not there)
1: I matched by V?I{1} (with V not there)
2: II matched by V?I{2} (with V not there)
3: III matched by V?I{3} (with V not there)
4: IV matched by IV
5: V matched by V?I{0} (with V there)
6: VI matched by V?I{1} (with V there)
7: VII matched by V?I{2} (with V there)
8: VIII matched by V?I{3} (with V there)
9: IX matched by IX
Tieni presente che quel regex corrisponderà anche a una stringa vuota. Se non vuoi questo (e il tuo motore regex è abbastanza moderno), puoi usare look-behind e look-ahead positivi:
(?<=^)M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})(?=$)
(l'altra alternativa è semplicemente verificare che la lunghezza non sia zero in anticipo).