Sono due metriche diverse per valutare le prestazioni del tuo modello, che di solito vengono utilizzate in fasi diverse.
La perdita viene spesso utilizzata nel processo di addestramento per trovare i valori dei parametri "migliori" per il proprio modello (ad es. Pesi nella rete neurale). È ciò che si tenta di ottimizzare nell'allenamento aggiornando i pesi.
La precisione è più da una prospettiva applicata. Una volta individuati i parametri ottimizzati sopra, utilizzate queste metriche per valutare l'accuratezza della previsione del modello rispetto ai dati reali.
Facciamo un esempio di classificazione dei giocattoli. Vuoi prevedere il sesso dal proprio peso e altezza. Hai 3 dati, sono i seguenti: (0 sta per maschio, 1 sta per femmina)
y1 = 0, x1_w = 50 kg, x2_h = 160 cm;
y2 = 0, x2_w = 60 kg, x2_h = 170 cm;
y3 = 1, x3_w = 55kg, x3_h = 175cm;
Si utilizza un modello di regressione logistica semplice che è y = 1 / (1 + exp- (b1 * x_w + b2 * x_h))
Come trovi b1 e b2? si definisce prima una perdita e si utilizza il metodo di ottimizzazione per minimizzare la perdita in modo iterativo aggiornando b1 e b2.
Nel nostro esempio, una perdita tipica per questo problema di classificazione binaria può essere: (un segno meno dovrebbe essere aggiunto davanti al segno di somma)

Non sappiamo cosa dovrebbero essere b1 e b2. Facciamo un'ipotesi casuale diciamo b1 = 0.1 e b2 = -0.03. Allora qual è la nostra perdita ora?
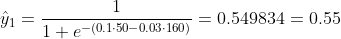
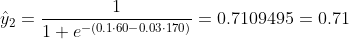
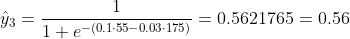
quindi la perdita è
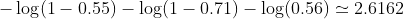
Quindi l'algoritmo di apprendimento (ad es. Discesa gradiente) troverà un modo per aggiornare b1 e b2 per ridurre la perdita.
Cosa succede se b1 = 0.1 e b2 = -0.03 è l'ultimo b1 e b2 (uscita dalla discesa del gradiente), qual è la precisione ora?
Supponiamo che y_hat> = 0,5, decidiamo che la nostra previsione è femminile (1). altrimenti sarebbe 0. Pertanto, il nostro algoritmo prevede y1 = 1, y2 = 1 e y3 = 1. Qual è la nostra precisione? Facciamo una previsione errata su y1 e y2 e ne facciamo una corretta su y3. Quindi ora la nostra precisione è 1/3 = 33.33%
PS: Nella risposta di Amir , si dice che la retro-propagazione sia un metodo di ottimizzazione in NN. Penso che sarebbe trattato come un modo per trovare il gradiente per i pesi in NN. Metodo di ottimizzazione comune in NN sono GradientDescent e Adam.
