Ken ha già sintetizzato alcuni dei motivi nella sua risposta . Per espanderci ulteriormente
- Più cache , che è più veloce della RAM
Ovviamente cache più grandi hanno bisogno di più transistor. Ma con più transistor abbiamo anche la possibilità di utilizzare cache più veloci . Le cache della CPU sono solo SRAM, che in genere è costituito da 6 transistor (AKA 6T SRAM). Tuttavia, quando ci sono abbastanza transistor, può valere la pena usare celle SRAM più veloci ma più grandi fatte da più di 6 transistor (come 8T, 10T SRAM)
- Altre istruzioni SIMD , che vengono elaborate più rapidamente rispetto alle istruzioni per dati singoli
Non solo SIMD ma qualsiasi tipo di istruzioni di accelerazione. Ad esempio, le architetture moderne spesso dispongono di un'unità AES per una crittografia / decrittografia più rapida, FMA per un migliore calcolo matematico (in particolare l'elaborazione del segnale digitale) o virtualizzazione per macchine virtuali più veloci. Supportare più istruzioni significa che sono necessarie più risorse per decodificarle ed eseguirle
- Più core , così puoi fare due o più cose contemporaneamente
- Pipeline , quindi ogni core può fare più cose contemporaneamente
Questi sono abbastanza chiari
- Unità più funzionale, come built-in FPU s, e multiple ALU s
In passato non vi era abbastanza superficie per gli stampi per l'FPU, quindi le persone devono acquistarne uno separato se hanno elevati requisiti di aritmetica in virgola mobile. Con molti più transistor è possibile avere la FPU integrata, che accelera molto la matematica in virgola mobile
Inoltre, le moderne CPU sono superscalari e proveranno a fare più cose contemporaneamente trovando pezzi di dati indipendenti e calcolandoli prima, anche se il flusso di istruzioni è lineare e seriale. Più cose possono fare in parallelo più velocemente saranno. Per fare ciò una CPU può avere più ALU e una ALU può avere più unità di esecuzione. Se ad esempio una CPU ha 5 adder rispetto a 4 della generazione precedente, allora è già in esecuzione del 25% più veloce nella situazione più ottimistica senza cambiamenti di clock. Le CPU più sofisticate impiegano persino l' esecuzione fuori servizio (come nel caso della maggior parte delle moderne CPU ad alte prestazioni)
Le operazioni possono in genere essere eseguite in vari modi. Se hai più transistor avrai più risorse per usare una tecnica più veloce. Alcuni semplici esempi:
Spostamento bit:
Un semplice cambio è realizzato collegando in serie le infradito insieme.

Ciò richiede solo un flip-flop per bit, quindi estremamente compatto. Ma ha bisogno di un orologio per spostarsi a sinistra o a destra di un bit. Ecco perché i microcontrollori e le piccole CPU integrate hanno solo le istruzioni per spostarsi di uno. Vedere
Quando hai più transistor da spendere, puoi passare a un cambio a barilotto . Ora una CPU può spostare i bit in un singolo clock con il costo di centinaia o migliaia di transistor
aggiunta:
- Un semplice sommatore viene creato anche collegando gli additivi completi in serie. In questo modo un sommatore N-bit ha bisogno di N clock per completare il suo lavoro, il che non è certo quello che le persone si aspettano da una CPU
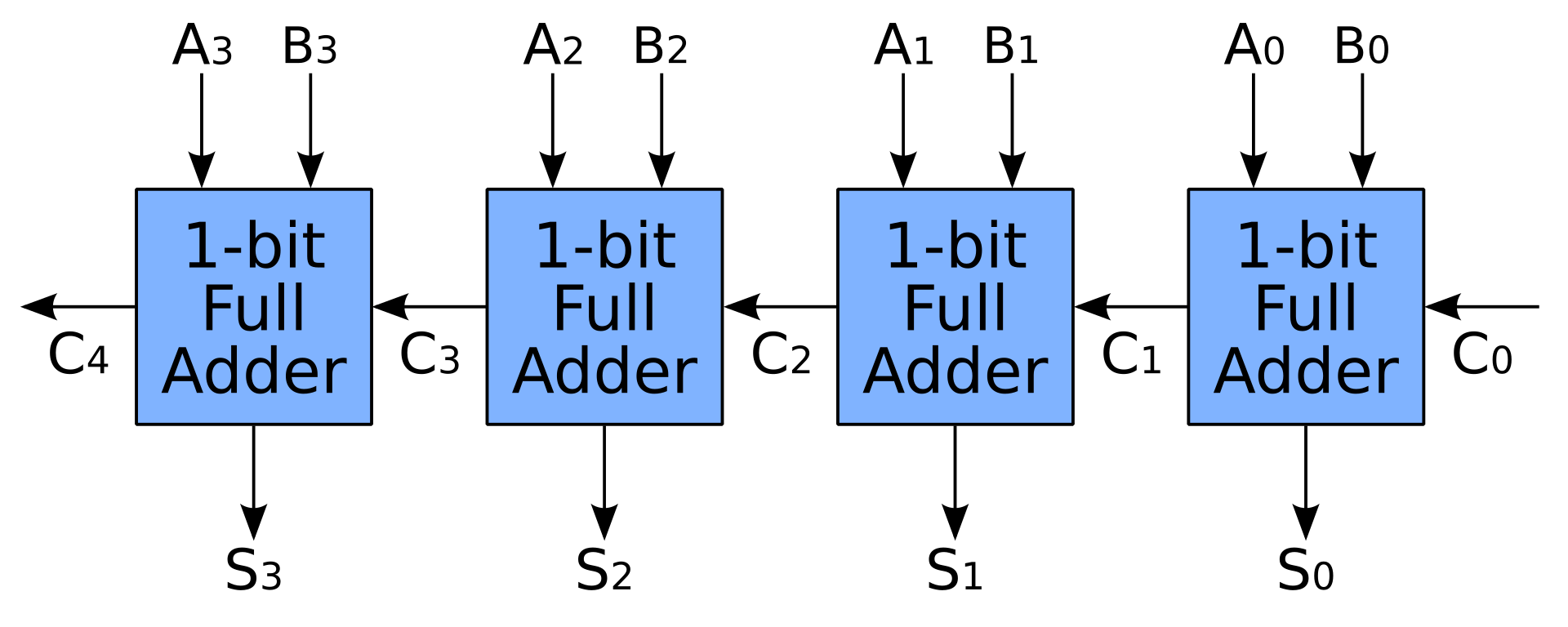
- Con più transistor possiamo accelerare l'aggiunta pre-calcolando i carry con carry-lookahead o carry-save adder. Gli additivi completi sono ancora utilizzati, ma è necessario molto più spazio per l'unità di pre-calcolo
La stessa cosa vale per altre unità come moltiplicatori, divisori, scheduler ... Ad esempio, possiamo fare una moltiplicazione estremamente veloce in un singolo clock usando la logica combinatoria . Puoi vedere alcuni semplici esempi nella domanda moltiplicatori a 3 bit: come funzionano? . Ma i transistor necessari cresceranno al quadrato delle larghezze di input, quindi le piccole CPU con un moltiplicatore usano la logica sequenziale invece di risparmiare molto spazio per il moltiplicatore:
Le architetture di moltiplicatori precedenti utilizzavano un cambio e un accumulatore per sommare ogni prodotto parziale, spesso un prodotto parziale per ciclo, scambiando velocità per l'area della matrice. Le moderne architetture a moltiplicatori utilizzano l'algoritmo (modificato) Baugh – Wooley, gli alberi di Wallace o i moltiplicatori Dadda per aggiungere i prodotti parziali in un singolo ciclo. Le prestazioni dell'implementazione dell'albero di Wallace sono talvolta migliorate da Booth modificato che codifica uno dei due moltiplicatori, il che riduce il numero di prodotti parziali che devono essere sommati
https://en.wikipedia.org/wiki/Binary_multiplier#Implementations
Una volta che hai un enorme pool di transistor puoi persino usare la logica combinatoria per fare un FMA che è molto più dispendioso in termini di risorse rispetto a un moltiplicatore
I computer moderni possono contenere un MAC dedicato, costituito da un moltiplicatore implementato in logica combinatoria seguito da un sommatore e da un registro accumulatore che memorizza il risultato. L'output del registro viene restituito a un input del sommatore, in modo che ad ogni ciclo di clock, l'output del moltiplicatore venga aggiunto al registro. I moltiplicatori combinati richiedono una grande quantità di logica, ma possono calcolare un prodotto molto più rapidamente rispetto al metodo di spostamento e aggiunta tipico dei computer precedenti.
Moltiplicare - accumulare operazioni

#/media/File:1-bit_full-adder.svg)