Nel loro documento sulla autoencoders per la classificazione di testo Hinton e Salakhutdinov dimostrato la trama prodotta da 2-dimensionale LSA (che è strettamente legata alla PCA): 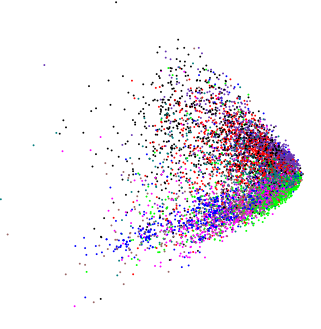 .
.
Applicando la PCA a dati dimensionali leggermente diversi e assolutamente diversi ho ottenuto una trama dall'aspetto simile:  (tranne in questo caso, volevo davvero sapere se c'è una struttura interna).
(tranne in questo caso, volevo davvero sapere se c'è una struttura interna).
Se inseriamo dati casuali nel PCA otteniamo un blob a forma di disco, quindi questa forma a cuneo non è casuale. Significa qualcosa da solo?
6
Presumo che tutte le variabili siano positive (o non negative) e continue? In tal caso, i bordi del cuneo sono solo i punti oltre i quali i dati diventerebbero 0 / negativi. Inoltre, puoi ottenere lo stesso modello che mostri con variabili positive distorte a destra; le osservazioni sono raggruppate nella parte bassa. Se avessi variabili casuali uniformi positive vedresti un quadrato (ruotato). Quindi modelli come quello che mostri sono solo dei vincoli sui dati. Altri modelli possono apparire, come un ferro di cavallo, ma questi non sono dovuti a vincoli sugli intervalli delle variabili.
—
Gavin Simpson,
@GavinSimpson Questo è molto più di un commento. Perché non espanderlo in una risposta?
—
Mike Hunter
Ho chiesto ai miei figli (3 e 4 anni) cosa ricordano loro queste foto e hanno detto che è un pesce. Quindi forse "forma simile a un pesce"?
—
amoeba,
@GavinSimpson, grazie! In entrambi i casi le variabili sono effettivamente non negative, anche in entrambi i casi sono valutate come numeri interi. Questo cambia qualcosa?
—
macleginn,







