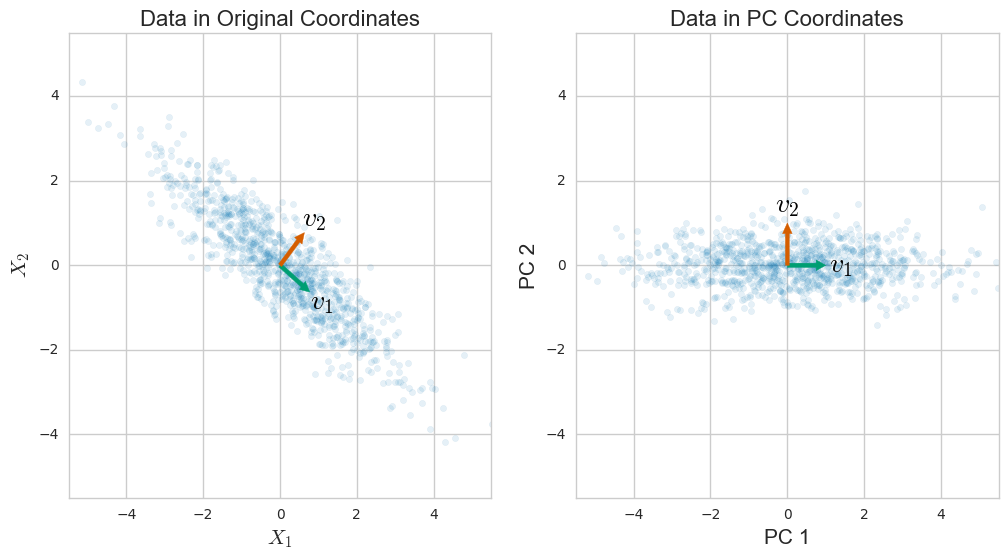
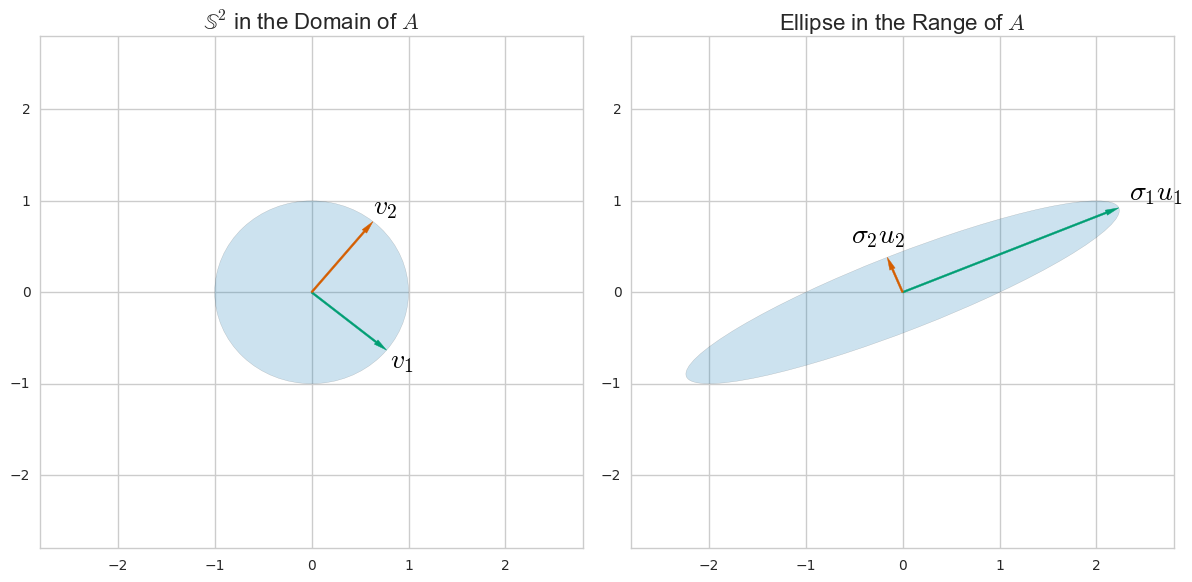
L'analisi dei componenti principali (PCA) viene di solito spiegata tramite una decomposizione degli automi della matrice di covarianza. Tuttavia, può anche essere eseguita mediante decomposizione in valori singolari (SVD) della matrice dati . Come funziona? Qual è la connessione tra questi due approcci? Qual è la relazione tra SVD e PCA?
O in altre parole, come utilizzare SVD della matrice di dati per eseguire la riduzione della dimensionalità?
8
Ho scritto questa domanda in stile FAQ insieme alla mia risposta, perché spesso viene posta in varie forme, ma non esiste un thread canonico e quindi è difficile chiudere i duplicati. Fornisci meta commenti in questo meta thread allegato .
—
ameba,
Oltre alla risposta un eccellente e dettagliata di amebe con i suoi ulteriori collegamenti potrei consigliare di controllare questo , dove PCA è considerato fianco a fianco alcune altre tecniche SVD-based. La discussione qui presenta un'algebra quasi identica a quella dell'ameba con una piccola differenza che il discorso lì, nel descrivere PCA, parla della decomposizione svd di [o ] invece di - che è semplicemente conveniente in quanto si riferisce alla PCA effettuata tramite la composizione elettronica della matrice di covarianza. X/ √ X
—
ttnphns,
PCA è un caso speciale di SVD. PCA ha bisogno di dati normalizzati, idealmente stessa unità. La matrice è nxn in PCA.
—
Orvar Korvar,
@OrvarKorvar: Di quale matrice nxn stai parlando?
—
Cbhihe,