Questa domanda nasce dalla mia attuale confusione su come decidere se un modello logistico è abbastanza buono. Ho modelli che usano lo stato delle coppie progetto individuale due anni dopo che si sono formati come una variabile dipendente. Il risultato ha esito positivo (1) o meno (0). Ho variabili indipendenti misurate al momento della formazione delle coppie. Il mio obiettivo è verificare se una variabile, che ho ipotizzato, influenzerebbe il successo delle coppie ha un effetto su quel successo, controllando altre potenziali influenze. Nei modelli, la variabile di interesse è significativa.
I modelli sono stati stimati utilizzando la glm()funzione in R. Per valutare la qualità dei modelli, ho fatto alcune cose: glm()ti dà il residual deviance, il AICe il BICdi default. Inoltre, ho calcolato il tasso di errore del modello e tracciato i residui binnati.
- Il modello completo ha una devianza residua minore, AIC e BIC rispetto agli altri modelli che ho stimato (e che sono nidificati nel modello completo), il che mi porta a pensare che questo modello sia "migliore" degli altri.
- Il tasso di errore del modello è piuttosto basso, IMHO (come in Gelman e Hill, 2007, pp.99 ):
error.rate <- mean((predicted>0.5 & y==0) | (predicted<0.5 & y==1)circa il 20%.
Fin qui tutto bene. Ma quando tracciamo il residuo in scatola (sempre seguendo i consigli di Gelman e Hill), gran parte dei contenitori cadono al di fuori dell'IC del 95%:
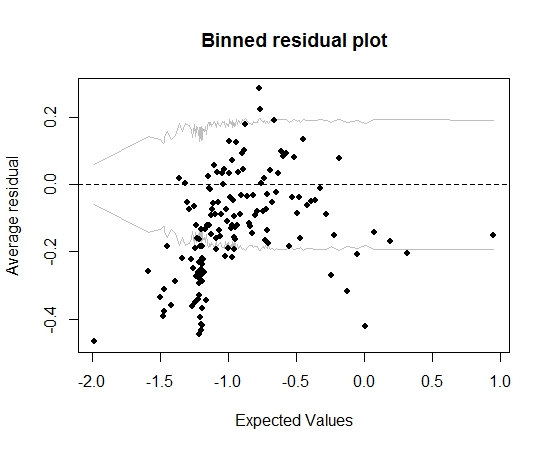
Quella trama mi porta a pensare che ci sia qualcosa di completamente sbagliato nel modello. Questo dovrebbe portarmi a buttare via la modella? Devo riconoscere che il modello è imperfetto, ma tenerlo e interpretare l'effetto della variabile di interesse? Ho giocato con l'esclusione delle variabili a loro volta, e anche con alcune trasformazioni, senza davvero migliorare la trama dei residui.
Modificare:
- Al momento, il modello ha una dozzina di predittori e 5 effetti di interazione.
- Le coppie sono "relativamente" indipendenti l'una dall'altra, nel senso che si formano tutte in un breve periodo di tempo (ma non in senso stretto, tutte contemporaneamente) e ci sono molti progetti (13k) e molti individui (19k ), quindi una buona parte dei progetti è raggiunta da un solo individuo (ci sono circa 20000 coppie).